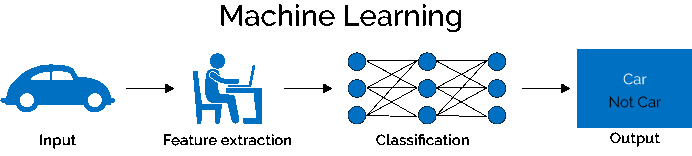
Machine Learning with Python
Bikash Santra
Research Scholar, Indian Statistical Institute, Kolkata
Python Packages
a) Image Input / Output: NumPy
b) Feature Extraction (Deep Convolutional Neural Network): pytorch
c) Classification (Deep Convolutional Neural Network): pytorch
d) Classification (Random Forest): scikit-learn
Convolutional Neural Network (CNN)¶
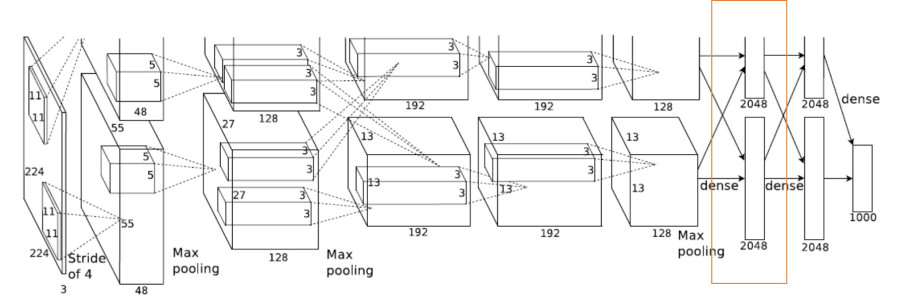
AlexNet [2012]- ImageNet Dataset
# Pytorch libraries
import torch
import torchvision
import torchvision.transforms as transforms
# For displaying images and numpy operations
import matplotlib.pyplot as plt
import numpy as np
# For CNN Purpose
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
# Loss function and optimizer
import torch.optim as optim
Initializing Data Loader¶
The output of torchvision datasets are PILImage images of range [0, 1]. We transform them to Tensors of normalized range [-1, 1]
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Functions to show an image¶
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# print(labels)
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Define a Convolution Neural Network¶
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(120, 84)
self.relu4 = nn.ReLU()
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
x = x.view(-1, 16 * 5 * 5)
x = self.fc1(x)
x = self.relu3(x)
x = self.fc2(x)
x2 = self.relu4(x)
x = self.fc3(x2)
return (x,x2)
net = Net()
print(net)
# Using GPU, if available
use_gpu = torch.cuda.is_available()
print(use_gpu)
if use_gpu:
net.cuda()
Define Loss function and optimizer¶
# Let’s use a Classification Cross-Entropy loss and SGD with momentum
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Train the network¶
# This is when things start to get interesting.
# We simply have to loop over our data iterator, and feed the inputs to the network and optimize
for epoch in range(20): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
# wrap them in Variable
if use_gpu:
inputs, labels = Variable(inputs.cuda()), \
Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
# zero the parameter gradients
optimizer.zero_grad()
outputs, features = net(inputs)
# forward + backward + optimize
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.data[0]
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
# Saving the model
torch.save(net.state_dict(), 'cifar10Model.pth')
# Loading the model
net.load_state_dict(torch.load('cifar10Model.pth'))
# Set model to evaluation mode
net.eval()
Feature Extraction and Classification using CNN¶
We have trained the network for 2 passes over the training dataset. But we need to check if the network has learnt anything at all.
We will check this by predicting the class label that the neural network outputs, and checking it against the ground-truth. If the prediction is correct, we add the sample to the list of correct predictions.
dataiter = iter(testloader)
images, labels = dataiter.next()
Okay, first step. Let us display an image from the test set to get familiar.
# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))

Okay, now let us see what the neural network thinks these examples above are:
if use_gpu:
outputs,_ = net(Variable(images.cuda()))
else:
outputs,_ = net(Variable(images))
# outputs = F.softmax(outputs)
outputs = outputs.cpu()
The outputs are energies for the 10 classes. Higher the energy for a class, the more the network thinks that the image is of the particular class. So, let’s get the index of the highest energy:
_, predicted = torch.max(outputs.data, 1)
predicted = predicted.numpy()
className = list(classes)
print('Predicted: ', ' '.join('%5s' % className[predicted[j]]
for j in range(4)))
The results seem pretty good.
Let us look at how the network performs on the whole dataset.
correct = 0
total = 0
for data in testloader:
images, labels = data
if use_gpu:
outputs,_ = net(Variable(images.cuda()))
outputs = outputs.cpu()
else:
outputs,_ = net(Variable(images))
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
Hmmm, what are the classes that performed well, and the classes that did not perform well:
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
for data in testloader:
images, labels = data
if use_gpu:
outputs,_ = net(Variable(images.cuda()))
outputs = outputs.cpu()
else:
outputs,_ = net(Variable(images))
_, predicted = torch.max(outputs.data, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i]
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
Feature Extraction using CNN¶
Train Set of CIFAR-10 Dataset
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
# wrap them in Variable
if use_gpu:
inputs, labels = Variable(inputs.cuda()), \
Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
# extracting features
_, features = net(inputs)
if use_gpu:
features = features.cpu()
labels = labels.cpu()
feature = features.data.numpy()
label = labels.data.numpy()
label = np.reshape(label,(labels.size(0),1))
if i==0:
featureMatrix = np.copy(feature)
labelVector = np.copy(label)
else:
featureMatrix = np.vstack([featureMatrix,feature])
labelVector = np.vstack([labelVector,label])
print('Finished Feature Extraction for Train Set')
Test Set of CIFAR-10 Dataset
for i, data in enumerate(testloader, 0):
# get the inputs
inputs, labels = data
# wrap them in Variable
if use_gpu:
inputs, labels = Variable(inputs.cuda()), \
Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
# extracting features
_, features = net(inputs)
if use_gpu:
features = features.cpu()
labels = labels.cpu()
feature = features.data.numpy()
label = labels.data.numpy()
label = np.reshape(label,(labels.size(0),1))
if i==0:
featureMatrixTest = np.copy(feature)
labelVectorTest = np.copy(label)
else:
featureMatrixTest = np.vstack([featureMatrixTest,feature])
labelVectorTest = np.vstack([labelVectorTest,label])
print('Finished Feature Extraction for Test Set')
Classification Using Random Forest¶
# Import Packages for Random Forest
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.externals import joblib
from sklearn.ensemble import RandomForestClassifier
# Defining Random Forest Claasifier
clf = RandomForestClassifier(n_estimators = 100)
print(clf.get_params())
# Train the Random Forest using Train Set of CIFAR-10 Dataset
clf.fit(featureMatrix, np.ravel(labelVector))
# Test with Random Forest for Test Set of CIFAR-10 Dataset
labelVectorPredicted = clf.predict(featureMatrixTest)
Glimpse of Classifcation Results¶
labelVectorTest = np.ravel(labelVectorTest)
className = list(classes)
print('GroundTruth', 'Predicted')
print('--------', '--------')
for i in range(10):
print(className[labelVectorTest[i]], className[labelVectorPredicted[i]])
Classification Performance over Whole Test Dataset¶
correct = (labelVectorPredicted == labelVectorTest).sum()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / labelVectorTest.shape[0]))
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
c = (labelVectorPredicted == labelVectorTest).squeeze()
for i in range(labelVectorTest.shape[0]):
label = labelVectorTest[i]
class_correct[label] += c[i]
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
Determining Feature Importance using Random Forest¶
print(clf.feature_importances_)
# Saving and loading models
joblib.dump(clf, 'fc1_forest1.pkl')
ctl = joblib.load('fc1_forest1.pkl')
References
a) http://pytorch.org//
b) http://scikit-learn.org/stable/
c) Ho, Tin Kam. "Random decision forests." In Document analysis and recognition, 1995., proceedings of the third international conference on, vol. 1, pp. 278-282. IEEE, 1995.
d) Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." In Advances in neural information processing systems, pp. 1097-1105. 2012.
Click here to download the source code of this tutorial.