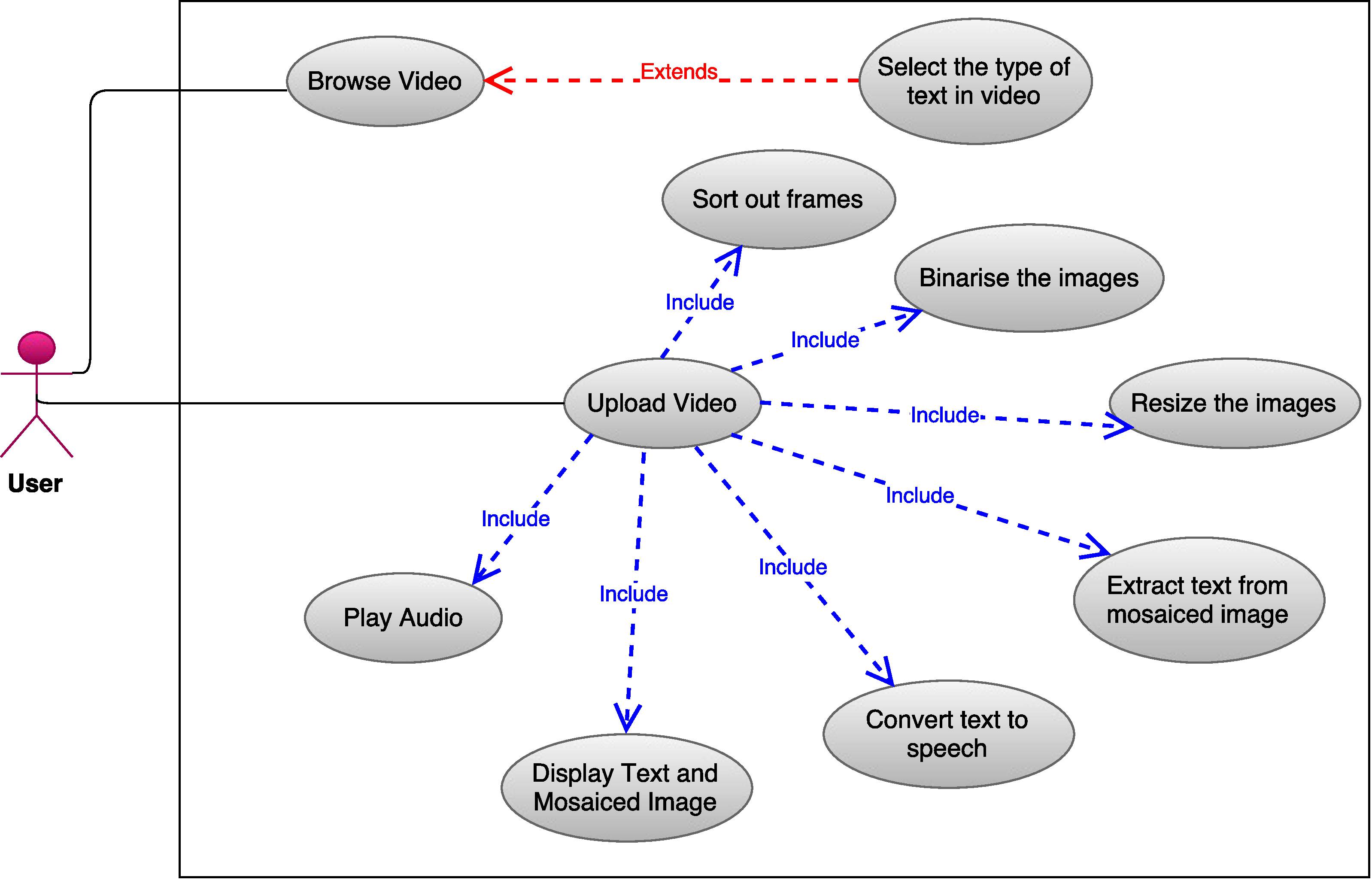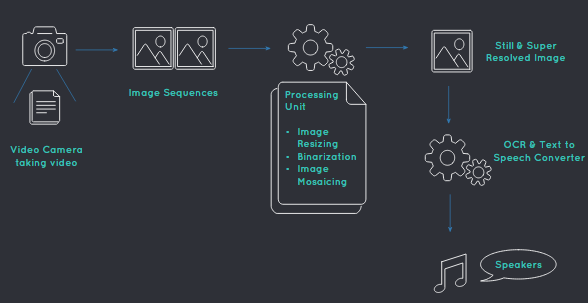
Objective is the development of an interface to textual information for the visually impaired that uses video, image processing, optical-character-recognition (OCR) and text-to-speech (TTS). The video provides a sequence of low resolution images in which text must be detected, rectified and converted into high resolution rectangular blocks that are capable of being analyzed via off-the-shelf OCR. To achieve this, various problems related to feature detection, mosaicing, binarization, and systems integration were solved in the development of the system.
For getting the image sequences, frames are cut at regular interval from the video, then pre-processes that image to get a clearer image. After that, using image stiching tool of OpenCV Python, a single image of the whole text is generated. Thereafter, that image is given to the OCR (Tesseract), which further give it’s output to the Google Text To Speech engine (gTTS) to make a final audio speech output.